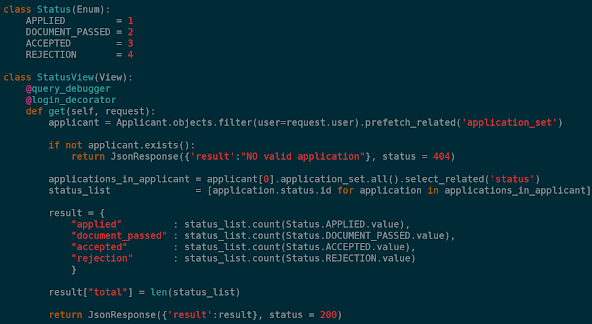
1. 안전
: 계속해서 메서드를 호출해도 리소스를 변경하지 않습니다.
GET은 안전 속성을 가지고 있으나, POST,PUT,PATCH 등은 호출했을 때 리소스의 변경이 일어나기 때문에 안전하지 않습니다.
2. 멱등 Idempotent => f(f(x) = f(x)
: 호출의 건수와 상관 없이 호출 결과가 항상 동일합니다.
GET은 서버에서 리소스를 불러오는 메서드이기에 멱등합니다.
DELETE 요청을 여러번 하여도, 삭제된 결과 자체는 똑같기에 DELETE는 멱등합니다.
PUT의 경우, 리소스를 완전히 "덮어쓰는" 메서드이기 때문에 여러번 요청하여도 같은 값으로 덮어쓰기에 멱등합니다. 리소스를 매 요청시마다 갱신하기에 멱등성이 생기는 것입니다.
그러나 POST는 멱등하지 않습니다. 예를 들어, POST를 통해 이미지를 업로드 할때, 여러번 POST하게 되면 중복 업로드가 될 수 있습니다.
더 심각하게는, POST를 통해서 결제를 처리하는 상황을 생각해 볼 수 있습니다.
- 클라이언트는 POST를 통하여 결제 요청을 보냅니다.
- 서버는 결제 요청을 받고, 결제 로직을 실행합니다.
이때 결제를 3번 요청하게 된다면, 3번의 중복 결제가 이뤄질 것입니다. 클라이언트 입장에서는 한번의 결제를 원하겠지만, 클라이언트의 의도와 다르게 여러번 결제가 중복해서 일어났습니다. 이처럼 POST는 멱등하지 않습니다
PATCH의 경우도 리소스의 일부를 변경하는 작업이기에, 멱등하지 않습니다.
멱등한 메서드들을 이용하여 자동 복구 메커니즘을 구현할 수 있습니다.
DELETE를 요청했는데, 서버에서 응답이 없다면 클라이언트는 다시금 DELETE를 요청할 수 있습니다. 이는 DELETE가 몇 번 호출하든 같은 결과를 내는 메서드라는 점을 활용하여, 클라이언트에서 임의적으로 재차 요청을 하는 것입니다.
이를 통하여 멱등성을 구분하는 이유를 알 수 있습니다.
서버 입장에서, 요청 실패 이후 재전송된 요청을 처리해도 괜찮은가? 에 대한 가이드를 제공해 주는 것이 멱등성입니다.
3. 캐시 가능
캐시 가능이라 함은 , 요청한 응답의 리소스를 향후 재사용을 위해 저장할 수 있는 속성을 의미합니다.
웹 캐시는 중간에 요청을 가로채, 서버로부터 리소스를 직접 다운로드 하는 대신, 리소스의 복사본을 반환합니다.
응답 결과 리소스를 캐시해서 사용해도 괜찮을까요?
이론적으로 GET,POST,PATCH 메소드는 캐시가 가능하다고 하지만, 실제로는 GET정도만 캐시를 사용할 수 있습니다.
웹 캐시는 리소스를 보여주는데 필요한 시간을 줄여서, 웹 사이트를 더 빠르게 만들 수 있는 방법입니다.
캐시에는 두가지 종류가 있습니다.
1. 사설(Private)
2. 공유(Shared)
Shared cache는 한 명 이상의 사용자가 재사용 할 수 있도록 응답을 저장한 캐시인 반면,
Private cache는 한 명의 사용자만 사용하는 캐시입니다.
대표적인 사설캐시로는 "브라우저 캐시"가 있습니다. 사용자가 http요청 이후 다운로드한 문서들을 저장하고 있다가, 앞뒤로 움직이기, 저장 등을 수행할 때 추가적인 서버 요청 없이 캐시를 활용합니다.
프록시캐시는 대표적인 공유 캐시입니다. 회사 혹은 ISP(Internet Service Provider)는 여러 사용자들을 위해 로컬 네트워크의 일부로 웹 프록시를 설치할 수 있습니다. 이를 통해 공통적으로 조회가 많이 되는 리소스들은 재사용되어 성능을 향상할 수 있습니다.