1. 프로젝트 소개
- 술담화 사이트를 모티브로 한, 차를 판매하는 차담화란 사이트를 구현하는 것이 목표
- 2주란 시간적 제약으로 인하여, 많은 기능을 목표로 하지 않았고, 해당 기능 구현에 집중
- 로그인/회원가입
- 테마별 정렬이 들어간 메인페이지
- 필터링과 정렬 기능이 들어간 전체 상품 리스트 페이지
- 상품 상세 페이지
- 장바구니 페이지
- 애자일한 프로젝트 진행을 위해 스크럼 방식으로 프로젝트를 진행(하려 했습니다만...)
- 2주간의 프로젝트 과정을 1,2차 스프린트로 나눠서 진행
- 각 스프린트의 시작마다 플래닝 미팅 진행
- 데일리 스탠드업 미팅을 통해 각자 진행과정과 블록커등을 공유
- 진행과정을 시각화하기 위하여 칸반 툴을 활용
2. 사용된 기술
공용 툴
- Trello: 칸반 생산성 툴인 트렐로를 활용했습니다. Backlog, To Do, In practice, Reviewing, Done으로 카드의 카테고리를 분류하여 각 카드에 해야 할 업무를 기록했습니다.
- GitHub : 프로젝트의 버전 관리와, 개발 과정에서의 협업을 위하여 백엔드와 프론트엔드의 깃헙을 분리하여 운영했습니다. main 브랜치를 건드리지 않고, 각 기능 구현을 별도의 브랜치에서 마친 후, 이를 메인과 merge시키면서 프로젝트를 진행했습니다. 팀원들이 머지 권한을 갖지 않고, 멘토님이 팀원들의 코드를 최종 리뷰한 이후 main에 머지시키는 방식으로 진행했습니다.
- Notion: 회의록을 노션으로 공유했습니다
- Slack
BE
- Mysql: 관계형 데이터베이스 관리시스템인 mysql을 활용했습니다
- Django : 파이썬 웹 프레임워크인 장고를 활용했습니다. MV패턴을 활용했습니다
- 프로젝트를 위한 환경설정은 conda 가상환경을 만들어, 이 가상환경으로 프로젝트를 진행하였습니다
개인 툴
- Notion : 앞서 회의록으로 노션을 활용한 것과 별개로, 개인적으로 1차 프로젝트 전용 노션 페이지를 별도로 구성하여 프로젝트 전반에 대해 기록했습니다.
3. 목표
- 팀 목표 : 기능 구현보다도, 소통과정에 있어 팀원들간 분쟁 없이 화목하게 프로젝트를 마무리하는 것이 목표였습니다. 결론적으로 상호간의 트러블 없이 무사히 프로젝트를 마칠 수 있었기에, 목표를 성공적으로 이룬 듯 합니다.
- 개인 목표 : 맡은 바 기능을 충실히 구현하면서, 구현 과정에 있어서 자기주도적인 해결과 - 타인의 도움을 받는 것 사이의 균형을 유지하는 것을 목표로 했습니다. 블록커를 맞닥드리는 경우, 이전까지는 시간적 인풋이 들더라도 최대한 혼자 골머리를 앓으면서라도 해결하려 했습니다. 하지만 이번 프로젝트의 경우 팀 프로젝트라는 특성상, 진행과정에 있어 호흡을 맞춰가며 진행해야 했기에, 적당한 선에서 고민과 구글링을 마치고 다른 분들에게 도움 또는 키워드 아이디어를 얻으려 의도적으로 노력했습니다. 결론적으로 팀으로써 함께 라인을 맞춰가며 잘 진행하였습니다.
다만 아쉬웠던 점은 프로젝트 전반적으로 걸쳐 급한 마인드를 가지고 진행하다 보니, 주변을 살피지 않고 혼자서 달려가는 경향이 있었는데, 이에 대해서는 아쉬웠던 점에서 자세히 서술하겠습니다.
4. 기능 구현 - 내가 한 부분
제가 담당한 부분은 다음과 같습니다
1. DBuploader 구현
ORM 쿼리문으로 일일히 데이터를 등록하지 않고 , csv파일을 통해 대량으로 데이터를 등록할 수 있도록 DBuploader를 별도로 만들었습니다.
아쉬웠던 점은, 하나의 csv파일을 가지고 db의 모든 테이블에 들어갈 데이터를 모두 넣으려 하다보니, csv파일이 옆으로 매우 길어졌다는 것입니다.
서로 참조관계를 가진 테이블들끼리만 분류를 하여, 서로 관계가 없는 테이블들은 각각 다른
csv파일을 사용하여서 업로드를 진행할 수 있도록 해줄 수도 있었을 텐데, 그렇게 진행하지 않았습니다. 따라서 db에 파일을 업로드함에 있어서 좌우로 스크롤을 계속해야 해서 피로감이 느껴졌고, 테이블들간의 참조관계를 명확하게 확인하며 데이터를 집어넣기 힘들었습니다. 다음프로젝트에서도 dbuploader를 사용하게 될텐데, 여러개의 csv파일을 이용하여 db에 데이터를 넣어서 불편함을 덜면서 진행할 계획입니다.
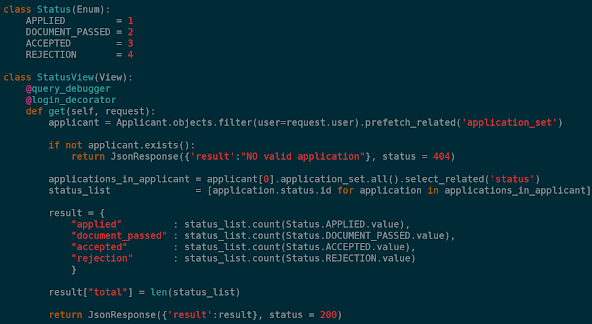
2. 상품 리스트 페이지 구현
제일 많은 시간과 노력을 쏟았던 View 입니다.
여러번코드를 들어내고 다시 작성하기를 반복했습니다.
앞서 블로그에,필터링 view를 공유했었는데, 여기서 몇번의 변경이 더 있었습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45 | class ProductView(View):
def get(self, request):
q = Q()
category = request.GET.getlist("category", None)
is_caffeinated = request.GET.get("is_caffeinated", None)
price_upper = request.GET.get("price_upper", 200000)
price_lower = request.GET.get("price_lower", 0)
search_query = request.GET.get('search_query', None)
if search_query:
q.add(Q(name__contains=search_query), Q.AND)
if category:
categories = category[0].split(',')
q.add(Q(category__name__in = categories), Q.AND)
if is_caffeinated:
q.add(Q(caffeine__gt=0), Q.AND) if is_caffeinated=="True" else q.add(Q(caffeine__exact=0), Q.AND)
q.add(Q(price__range = (price_lower, price_upper)),Q.AND)
drinks = Drink.objects.filter(q).annotate(average_rating = Avg('review__rating'), review_count=Count('review'))
sort_by = request.GET.get('sort_by', None)
sort_by_options = {
"newest" : "-updated_at",
"oldest" : "updated_at",
"highest_rating" : "-average_rating",
}
result = [{
"id" : drink.id,
"name" : drink.name,
"price" : drink.price,
"average_rating" : drink.average_rating if drink.average_rating else 0,
"review_count" : drink.review_count,
"image" : drink.drinkimage_set.all().first().thumb_img
}for drink in drinks.order_by(sort_by_options[sort_by])]
return JsonResponse({'result':result}, status = 200)
초 |
최종적인 코드입니다.
절차적으로 if-elif로 코드를 작성한 것을 모두 들어내고, linear한 진행을 방해하는 불필요한 함수 import또한 모두 제거했습니다.
프론트로부터 쿼리파라미터를 제공받아 이에 따라 필터링을 q 객체로 진행해주었으며, 필터링을 마친 쿼리셋에 대하여 정렬을 진행합니다.
정렬에 있어서 drink와 연결된 review 테이블의 ratings 컬럼의 평균을 내서 이에 따라 정렬을 해주는 부분이 매우 큰 블록커로 다가왔습니다. 처음에는 장문의 if-elif문을 작성하여 평균을 직접 작성해주었으나, 이를 제거하고 장고의 annotate기능을 활용하여 테이블에 존재하지 않는 새로운 컬럼을 만든 뒤, 이에 따라 정렬을 해 주었습니다.
q객체, annotate등 장고의 메소드들을 활용하여 코드를 작성하니 훨씬 가독성이 늘어나고 코드 작성이 편리해짐을 느낄 수 있었습니다. 해당 기능들을 사용하면서 공식문서의 위력을 느낄 수 있었습니다. 구글링을 통해 타 블로그 등의 소스를 사용하는 것보다, 공식문서를 집중하여 읽어내고, 이해한 바를 바탕으로 나의 코드에 적용시키는 것이 어렵지만 빠르고 확실하게 가는 방법임을 경험했습니다.
최신순, 오래된순, 평점순의 정렬도 원래는 if문을 사용하여 각각 경우의 수를 분기해 주었으나, 멘토님의 피드백을 받은 이후, 정렬의 경우의 수를 담은 딕셔너리인 sort_by_options를 만들고, 쿼리 파라미터의 키값을 통해 정렬 방법을 전달받아 분기 없이 바로 .order_by 의 인자로 주는 방식으로 변경하였습니다. 이 또한 선형적인 코드 진행에 대해 배울 수 있는 과정이었습니다. 이처럼 많은 것을 배운 코드였습니다
3. 테마(농장)별 정렬이 들어간 메인 페이지
사용한 메소드는 필터링과 대동소이하나, 두개의 컴프리헨션을 중첩해서 사용해서 다소 난항을 겪었던 View입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33 | class FarmProductView(View):
def get(self, request):
offset = request.GET.get("offset", 0)
limit = request.GET.get("limit", 4)
order_method = request.GET.get("order_method", "highest_rating")
order_method_options = {
"highest_rating" : "-average_rating",
"newest" : "-updated_at",
"oldest" : "updated_at"
}
farms = Farm.objects.all()
result = {
"farm" : [{
"id" : farm.id,
"name" : farm.name,
"drinks" : [
{
"id" : drink.id,
"name" : drink.name,
"price" : drink.price,
"average_rating" : drink.average_rating,
"review_count" : drink.review_count,
"image" : drink.drinkimage_set.all().first().thumb_img,
} for drink in farm.drink_set.all().annotate(average_rating = Avg('review__rating'), review_count=Count('review'))\
.order_by(order_method_options[order_method])[offset:offset+limit]]
} for farm in farms]
}
return JsonResponse({'result':result}, status = 200)처 |
5. 협업 경험
혼자서 장고로 model과 view로 백엔드 로직을 작성하고, postman으로 crud를 확인하는 과정과 다르게, 여러명의 백엔드와, 거기에 프론트엔드 팀원들까지 함께한 협업 경험은 새롭고도 즐거운 경험이었습니다. 협업을 진행하며 이러한 것들을 느꼈습니다.
프로젝트를 진행하며 정말 많은 정기적인 미팅과, 비공식적인 대화를 나누었습니다. 말을 정말 정말 많이하게 되는데, 돌아서면 그 많은 말들을 다 까먹게 되는 신기한(?) 경험을 했습니다. 분명히 서로 구두로 어떠한 점을 협약하거나 정보를 공유했는데, 나중에 보면 둘다 이를 까먹고 있는 사태가 발생했습니다. 일례로 메인 페이지에서 농장별 상품 정렬을 백엔드측은 3가지로 기억하고 이에 따라 DB데이터 작성을 완료했는데, 사이트 시연 전날 얘기를 나눠보니 프론트측은 이를 6개로 기억하고 있어서 그에 맞게 사이트UI를 만들어 놓았던 일이 있었습니다. 말을 한 즉시 어딘가에 기록해두었다면 서로 혼선을 일으켜서 마지막에 고생하는 일은 없었을 것입니다. 개인적으로 최대한 대화를 나누면 바로바로 노션에 저장하려 했으나, 주먹구구식으로 적다보니깐 체계화가 되지 못했던 점은 아쉽습니다.
다음 프로젝트때는 팀으로서의 기록을 trello를 통해 직관적으로 공유하면서, 개인적으로는 기능별/ 날짜별로 섹션을 나누어 기록을 더 상세히 진행해볼까 합니다.
모델링을 변경하는 소요는 프로젝트를 진행하면서 어쩔 수 없이 생기는 일인 듯 하지만, 그래도 이를 최소화하는 것이 좋다고 느꼈습니다. 프로젝트 진행 중간에 이에 대한 인풋 투입이 생기다보니 일정에 차질이 생김을 느꼈습니다.
일례로, 상품상세페이지에서 상품 상세설명 이미지를 프론트측이 하드코딩하기로 하여 이에 대한 db컬럼을 따로 마련하지 않고 있다가, 후에 하드코딩에 들어가는 소요가 너무 큼을 깨닫고 뒤늦게 db에 상세설명 이미지를 위한 컬럼을 따로 만들어주었습니다. 이 과정에서 각 테이블들간의 참조관계가 변경되어 db를 완전히 들어내고 migrate를 다시 진행했습니다. 이 과정에서 마저도 한번의 db 삭제이후 마이그레이트로 끝난것이 아니라, 여러 문제가 생겨서 db삭제와 마이그레이트를 여러번 반복했던 것이 기억이 납니다. 이때 멘탈이 깨져서 어떠한 문제들을 겪었는지 기록해놓지를 않았는데, 다시한번 바로바로 기록으로 남기는 것의 중요성을 블로그를 작성하며 느낍니다... 그냥 되게 고생을 했다는 것만 기억이 나네요..ㅋㅋ
6. 아쉬운 점
- 회의록을 따로 만들지 말고 트렐로 카드에 직접 기록했으면 어떨까 싶습니다
회의록을 따로 노션페이지를 만들어서 작성했다고 했는데, 그러다 보니 트렐로/ 노션 두 툴을 전환해가면서 일정과 협의사항을 확인하는 것이 불편했습니다. 다른 조원분들을 보면 트렐로에 직접 회의 사항을 정리해서 기록하신 조들이 있던데, 이러한 방식이 더 효율적이라고 느꼈습니다. 협업 툴은 적을수록, 간결할 수록 좋은 듯합니다
앞서 혼자서 너무 달렸던 경향이 있다고 서술했는데, 이에 해당하는 부분입니다.
혼자서 달린다고 잘해지는 것도 아니고 나의 조급함만 배가 됐습니다. 급한마음에 이것저것 "구현" 그 자체에 목적을 두고 JSON파일 가는 것만 보고 PR을 급하게 날렸습니다. 그러나 이렇게 작성한 코드는 제대로 된 코드가 전혀 아니었고, 결론적으로 시간만 날린 꼴이 됐습니다. 스스로의 능력을 냉철하게 파악하고, 더 고민하여 체계적으로 , 천천히 접근했다면 마음도 편하고 프로젝트 진행도 한결 수월하게 되지 않았을까 하는 아쉬움이 남습니다.
2주간 그럼에도 불구하고 너무 고생많았고, 함께 고생한 팀원들에게 감사를 표하고 싶습니다. 훗날 돌아볼때 즐거웠고 유익했던 프로젝트로 남을 수 있는 좋은 경험을 한것 같아 뿌듯합니다.